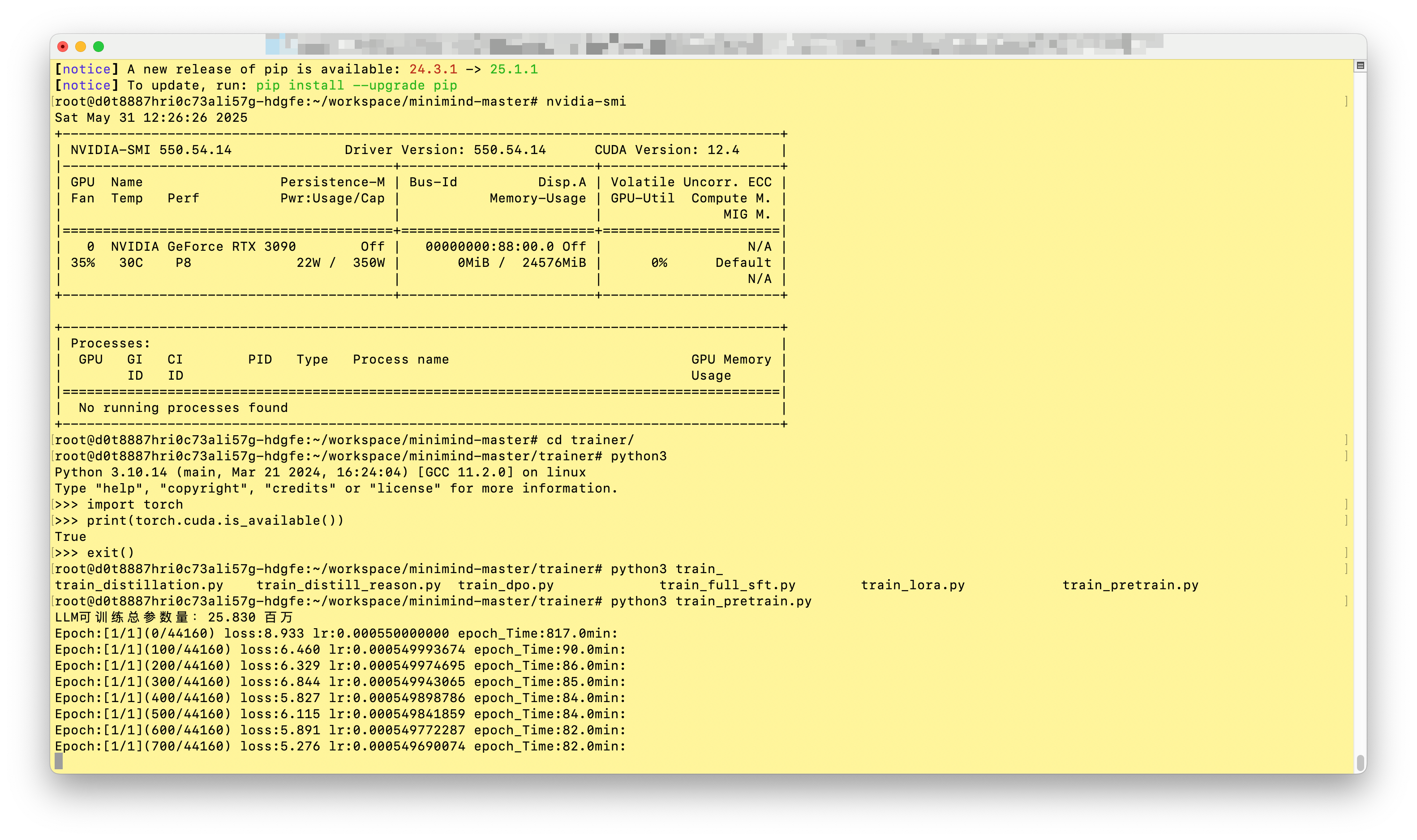
第一部分: Claude 范式——从助手到代理
第一章: 集成推理的哲学
超越代码补全: Claude 为深度理解而生的设计
在人工智能辅助软件开发的浪潮中,大多数工具都专注于提升编码的”战术”效率,即更快地编写代码行。然而,Anthropic公司的Claude模型,尤其是其编码能力,建立在一种截然不同的哲学之上:推理能力不应是模型的附加功能,而应是其与生俱来的核心。这种设计理念旨在模拟人类大脑处理信息的方式一一既能进行快速的本能反应,也能进行深入的、反思性的思考,从而为开发者提供一个无缝且强大的协作伙伴。
这种哲学的基石是Anthropic的”宪法式AI”(ConstitutionalAl)框架。该框架通过一系列预设的原则和规则来引导模型的行为,确保其输出不仅有用,而且安全、可靠且符合道德规范。对于专业开发环境而言,这意味着Claude不仅仅是一个代码生成器,更是一个值得信赖的、注重最佳实践的”AI工程师”。它会主动避免生成有害或不安全的代码,并倾向于提供结构良好、易于理解的解决方案,这与仅仅追求功能实现的工具形成了解明对比。
这种设计理念的深远影响在于,它将AI的角色从一个被动的”代码补全工具”转变为一个主动的“认知伙伴”。传统的AI助手主要增强了编码的编写阶段,而Claude的集成推理能力则旨在增强思考和规划阶段。在软件开发中,最具挑战性的部分往往不是编写代码本身,而是在编写之前进行问题的分解、架构的设计、边缘案例的考量以及潜在风险的评估。这正是开发者认知负荷最重的环节。Claude的设计正是为了分担这种认知负荷,通过提供一个能够自主规划、反思和优化解决方案的工具,它将开发者从繁重的战术思考中解放出来,使其能够更专注于战略层面的决策一一例如,审查AI的架构提议、指导其技术选型,以及最终确保方案的质量。这不仅提升了开发效率,更从根本上改变了开发者的工作模式,将其角色提升为AI团队的技术架构师和审查者。
标准模式 vs. 扩展思考模式: 何时让 Claude “思考”
为了将集成推理的哲学付诸实践,Claude 3.7 Sonnet 等先进模型引入了一种创新的混合架构,使
其能够根据任务的复杂性在两种模式之间切换:标准模式和“扩展思考”(Extended Thinking)模式1。
- 标准模式:在此模式下,Claude 表现为一个高效的语言模型,能够对常规请求做出快速响应。这适用于生成样板代码、编写简单的函数或进行快速的代码片段转换等任务。其性能是对 Claude 3.5 Sonnet 的升级,保证了日常任务的流畅性1。- 扩展思考模式:当面对复杂问题时,开发者可以激活此模式。在这种模式下,Claude 会在给出最终答案之前,进行一个内部的“自我反思”或“头脑风暴”过程3。它会分解问题,规划步骤,评估不同的解决方案,并考虑潜在的边缘案例3。这个过程对于复杂的算法设计、多步骤逻辑推理、疑难 bug 调试以及系统架构规划至关重要1。
对于API用户,Claude提供了对”思考预算”的精细控制。开发者可以设定一个思考过程中允许消耗的token数量上限,从而在成本、响应速度和答案质量之间做出权衡。这种灵活性对于在生产环境中构建依赖AI的自动化工作流至关重要,因为它允许开发者根据具体应用场景(例如,实时代码审查vs.离线架构分析)来优化AI的性能和成本。
专注于真实世界任务:Anthropic的策略如何塑造工具
Anthropic的另一个关键策略是,将其模型的优化重点从学术性或竞赛性的编程基准,转向更能反映企业和开发者在实际工作中遇到的复杂问题的真实世界任务1。这意味着Claude的训练和评估更侧重于处理大型、混乱的代码库,执行多文件的重构,以及理解和实现模糊的业务需求,而非仅仅解决定义明确的算法难题。
这一策略的成果在早期采用者的反馈中得到了验证:
- Cursor评价Claude为”真实世界编码任务中的同类最佳”,尤其在处理复杂代码库和使用高级工具方面有显著提升。- Cognition发现Claude在规划代码变更和处理全栈更新方面远超其他模型。- Vercel强调了Claude在复杂代理工作流中的卓越精确性。- Replit成功利用Claude从零开始构建了复杂的Web应用和仪表盘,而其他模型在这些任务上常常停滞不前。- Canva的评估显示,Claude能够持续生成具有优秀设计品味且错误率极低的生产级代码1。
这些来自业界的真实反馈表明,Claude的能力并非停留在理论层面,而是真正为解决专业软件开发中的实际痛点而设计的。它是一个为工程师打造的工具,旨在应对充满依赖关系、历史遗留问题和不断变化的需求的真实项目环境。
第二章:Claude Code vs. GitHub Copilot:两种范式的较量
行内助手:Copilot在加速代码编写中的角色
GitHub Copilot已经成为现代软件开发中不可或缺的一部分,它完美地诠释了“AI结对程序员”的
角色8。其核心优势在于与集成开发环境(IDE)的无缝集成,以行内代码补全和实时建议的形式,极大地加速了代码的编写过程。当开发者已经有清晰的实现思路时,Copilot能够快速生成样板代码、补全函数、实现常见模式,从而显著减少手动输入,让开发者能够专注于更高层次的逻辑构建。Copilot的范式是战术性的、即时的。它在开发者思考和键入的”内循环”中发挥作用,其上下文感知主要局限于当前文件和少量打开的标签页。它是一个出色的加速器,但其设计初衷并非自主地承担复杂的、跨文件的开发任务。
代理式伙伴:ClaudeCode执行工作流的方法
与Copilot的行内辅助范式不同,ClaudeCode将自己定位为一个”代理式开发伙伴”(AgenticDevelopmentPartner)°。它在更高的抽象层次上运作,旨在理解并自主执行完整的、复杂的开发工作流1。开发者不是请求ClaudeCode补全一行代码,而是委托给它一个完整的任务,例如:“实现用户认证功能”、“重构支付模块以提高可维护性”或”修复这个bug并编写单元测试”。为了完成这些任务,ClaudeCode被赋予了更广泛的能力:
规划能力:在动手编码前,它会先制定一个详细的计划。·多文件操作:它能够读取、理解和修改项目中的多个文件,以完成一个跨越不同模块的功能。·工具使用:它可以运行shell命令,例如安装依赖、运行测试或执行构建脚本。·版本控制:它能与Git交互,创建分支、提交代码,甚至创建拉取请求。
ClaudeCode的主场是命令行或IDE中的专用面板,它在开发的”外循环”中工作,处理的是需要跨文件上下文、需要规划和自动化的战略性任务。
为任务选择合适的工具:开发者的决策框架
理解ClaudeCode和GitHubCopilot之间的范式差异至关重要,因为它们并非相互替代,而是高度互补的工具。一个高效的开发者应该根据任务的性质来选择使用哪一个,甚至将两者结合使用。
决策框架如下:
使用GitHubCopilot:当你已经明确知道要做什么,处于编码的”心流”状态时。适用于快速编写函数、实现已知算法、填充样板代码以及减少重复性输入。·使用ClaudeCode:当你需要处理一个复杂的、定义尚不完全清晰的任务时。适用于实现一个新功能、进行大规模代码重构、调试一个涉及多个模块的疑难问题、编写全面的测试套件,或者需要自动化一系列开发步骤时。
一个典型的协同工作流可能是:
1.规划与初始实现:在ClaudeCode中,通过自然语言描述需求,让其生成一个初步的实现计划和核心代码框架,可能涉及多个文件的创建和修改。2.细节编码与优化:在IDE中,利用GitHubCopilot对ClaudeCode生成的代码进行微调、补全和优化,快速完成细节部分的编码。3.测试与重构:回到ClaudeCode,要求它为新实现的功能编写单元测试和集成测试,或者对
现有模块进行大规模的重构。
通过这种方式,开发者可以利用Claude Code的战略规划和自动化能力来处理宏观任务,同时利用Copilot的战术加速能力来处理微观的编码细节,从而实现效率的最大化。
下表总结了这两种工具在核心范式上的关键区别:
| 维度 | Claude Code | GitHub Copilot |
| 核心范式 | 代理式伙伴 (Agentic Partner) | 结对程序员 (Pair Programmer) |
| 主要交互界面 | 命令行 / IDE 专用面板 | IDE 内联建议 |
| 理想用例 | 复杂功能开发、大规模重构、自动化测试、端到端任务执行 | 样板代码生成、代码补全、函数实现、实时编码加速 |
| 工作单元 | 完整的任务或工作流(例如,“实现一个功能”) | 代码行或函数(例如,“补全这个循环”) |
| 上下文感知 | 整个项目目录(通过文件系统访问和 CLAUDE.md) | 当前文件及少量打开的标签页 |
| 核心优势 | 深度推理、自主规划、多文件操作、工具链自动化 | 速度、与编码流程的无缝集成、简单易用 |
| 潜在挑战 | 学习曲线较陡,交互模式更偏向于“委托-审查” | 缺乏深度规划能力,难以处理跨文件的复杂依赖 |
第二部分:掌握Claude Code环境
第三章:命令行驾驶舱:深入解析Claude Code CLI
安装、认证与初始项目设置
将Claude Code集成到开发工作流的第一步是安装其核心工具——命令行界面(CLI)。这个过程非常直接,前提是系统中已安装Node.js 18或更高版本10。
安装:
通过Node.js包管理器(npm)进行全局安装是标准做法。在终端中运行以下命令15:
Bash
npm install - g @anthropic- ai/claude- code
这个命令会将claude可执行文件安装到系统的PATH中,使其可以在任何目录下调用。
认证:
首次运行claude命令时,系统会引导用户完成认证过程。主要有两种认证方式14:
- 通过Anthropic Console:使用Anthropic API密钥进行认证。这种方式基于实际使用量计费,适合需要精细成本控制或通过API进行集成的用户。2. 通过Claude.ai账户:关联一个拥有Pro或Max订阅的Claude.ai账户。这种方式提供了一个统一的订阅,覆盖了网页版和CLI的使用,对于个人开发者或小团队来说通常更具成本效益。
项目设置:
ClaudeCode的一个核心设计理念是“作用域限定”。为了让它能够安全地与你的代码交互,你应该在项目的根目录下启动它10。
Bash
cd /path/to/your- project claude
当你在特定目录中启动claude时,它会创建一个交互式会话(REPL),其文件访问权限被严格限制在该目录及其子目录内。这意味着ClaudeCode无法意外地修改项目之外的任何文件,提供了一个安全的工作沙箱。
驾驭三种核心模式:默认、自动与计划
ClaudeCode提供了三种不同的交互模式,开发者可以通过Shift+Tab快捷键在它们之间循环切换,以适应不同类型的工作任务15。
- 默认模式(Default Mode):这是最基础、最安全的模式。开发者发出指令,Claude Code分析后提出一个或一系列代码修改建议,然后暂停并等待用户的明确批准。只有在用户同意后,它才会执行文件写入或命令运行操作。这种“请求-批准-执行”的循环确保了开发者对每一步都有完全的控制权15。- 自动模式(Auto Mode):这种模式被社区称为“vibe coder”模式,旨在提供更流畅、更少中断的体验15。在自动模式下,Claude Code在接收到任务后会直接修改文件,无需每次都请求批准。为了安全起见,对于可能产生副作用的shell命令(如npm install),它仍然会请求许可。对于高度信任Claude Code的高级用户,可以通过“dangerously-skip-permissions”标志启动来完全禁用所有权限提示15。这种模式非常适合执行定义明确、风险较低的任务,让开发者可以专注于下一个目标,而AI则在后台自主工作。- 计划模式(Plan Mode):这是处理任何非凡任务时推荐使用的模式。在计划模式下,开发者首先向Claude Code描述一个高层次的目标或功能需求。Claude Code不会立即开始编码,而是会激活其“扩展思考”能力,生成一份详尽的实施计划15。这份计划通常包括技术选型、架构设计、文件结构、关键函数定义和实施步骤。开发者可以审查、修改这份计划,并与Claude Code进行多轮讨论,直到双方对方案达成共识。一旦计划被批准,Claude
Code 才会按照该计划开始具体的编码工作。这种“先规划,后执行”的方法极大地提高了复杂任务的成功率和最终代码的质量。
工作流管理的基本斜杠命令
Claude Code 的 CLI 提供了丰富的斜杠 (/) 命令,用于高效地管理会话、上下文和工具。掌握这些命令是提升生产力的关键。
- /init: 在项目目录中首次使用时,此命令会扫描整个项目结构,并自动生成一个 CLAUDE.nd 文件的初始版本。这个文件是 Claude Code 理解项目特定规范的起点3。- /permissions: 允许用户管理和配置哪些工具或 shell 命令可以无需提示直接运行。例如,你可以将常用的、安全的命令(如 npm test 或 git status)添加到白名单,以减少自动模式下的中断15。- /clear 和 /compact: 这两个命令用于管理宝贵的上下文窗口。当开始一个全新的任务时,使用 /clear 可以清空当前会话历史,确保 Claude Code 不受旧信息的干扰16。当会话历史很长但又不想完全丢失上下文时,/compact 会让 Claude Code 对之前的对话进行总结,保留关键信息,同时释放出 token 空间21。- /review 和 /security-review: 这些是专门用于代码分析的命令。/review 可以用于审查代码变更或整个文件,而 /security-review 则会调用一个专门的安全分析模型,检查代码中是否存在常见的安全漏洞,如 SQL 注入、XSS 等20。
无缝 IDE 集成:配置 VS Code 与 JetBrains
尽管 Claude Code 是一个强大的命令行工具,但其真正的潜力在于与 IDE 的深度集成。这种集成将 CLI 的强大功能与 IDE 的可视化和上下文感知能力结合在一起,创造了一个无缝的开发环境。自动安装:
集成过程非常简单。开发者只需在 IDE 的内置终端中首次运行 claude 命令,Claude Code 会自动检测到其运行环境(如 VS Code, Cursor, JetBrains IDEs),并提示安装相应的官方扩展或插件 24。
核心集成特性:
一旦集成完成,开发者将获得多项增强功能 24:
- 交互式差异视图 (Diff Viewing): 当 Claude Code 提议修改代码时,它不再仅仅在终端中显示文本差异。取而代之的是,它会在 IDE 中打开一个原生的、可视化的差异比较窗口。这使得审查、修改甚至部分接受代码变更变得极其直观和高效。- 自动上下文共享:IDE 插件能够将关键的上下文信息自动提供给 Claude Code。这包括当前在编辑器中选中的代码、光标所在位置、打开的标签页列表,甚至是诊断面板中的错误和警告信息。这意味着开发者无需手动复制粘贴代码或错误信息,只需简单地提问:“修复这里的这个错误”,Claude Code 就已经掌握了所有必要的上下文。- 键盘快捷键:集成还带来了方便的快捷键,例如,可以一键将选中的代码块发送到 Claude Code 的输入框,或者快速打开 Claude Code 的交互面板。
除了官方插件,社区也开发了一些第三方扩展,如 CodeGPT,它们提供了通过传统 API 密钥方式集成 Claude 模型的替代方案,为开发者提供了更多选择14。通过这些集成,Claude Code 从一个独立的命令行工具,转变为一个深度嵌入到开发者日常工作流程中的智能核心。
第四章:CLAUDE.md 文件:项目的“宪法”
仓库的“系统提示”:目的与功能
CLAUDE.md 文件是 Claude Code 最具变革性的特性之一。它不仅仅是一个普通的文档文件,而是作为整个项目的“系统提示”或“宪法”而存在31。每当 Claude Code 在一个项目中启动时,它会自动、优先地加载
CLAUDE.md 的内容,并将其中的指令视为不可违背的、权威性的系统规则31。这些规则的优先级高于用户在聊天中输入的任何临时性提示,从而确保了 AI 在整个项目生命周期中的行为一致性和可预测性。
这个文件的核心目的是弥合 AI 的通用知识与项目特定需求之间的鸿沟。它可以包含6:
- 编码规范:例如,变量命名约定、代码格式化规则、注释风格等。- 技术栈与框架:指明项目使用的主要技术、库版本以及特定的使用模式。- 测试指令:如何运行测试、测试文件的命名约定、首选的测试框架和断言风格。- 常用命令:构建、部署、数据库迁移等常用 shell 命令的列表和说明。- 架构原则:项目的高层架构决策、核心模块的功能摘要以及模块间的交互方式。- 版本控制礼仪:分支命名策略(如 Git Flow)、提交信息的格式要求等。
通过将这些“部落知识”显式地文档化在 CLAUDE.md 中,团队可以确保 Claude Code 生成的代码、提交的信息以及执行的操作都严格遵守项目的既定标准。
打造高效的 CLAUDE.md:简洁与清晰的最佳实践
一个高效的 CLAUDE.md 文件并非越长越好。恰恰相反,它的设计需要遵循“简洁与意图明确”的黄金法则32。因为该文件的内容会作为前缀被添加到每次与 Claude Code 的交互中,直接消耗宝贵的上下文 token 预算。一个冗长、混乱的 CLAUDE.md 不仅会增加成本,还可能引入噪声,干扰模型对核心指令的理解。
以下是打造高效 CLAUDE.md 的最佳实践:
- 从 /init 开始并持续迭代:无需从零开始。在项目中首次运行 claude 后,使用 /init 命令会自动生成一个包含基本结构的模板文件19。之后,应将 CLAUDE.md 视为一个“活文档”,随着项目的演进而不断更新和完善35。- 使用清晰的 Markdown 格式:采用项目符号、简短的句子和清晰的标题来组织内容。这比大段的叙述性文字更易于模型解析31。- 强调关键规则:对于绝对不能违反的规则,可以使用大写字母、加粗或明确的词语(如 “IMPORTANT:”、“MUST:”)来强调,模型会给予这些指令更高的关注度19。
层级的力量:在Monorepos中使用嵌套的CLAUDE.md文件
对于大型项目,尤其是采用monorepo(单一代码库)结构的项目,单一的CLAUDE.md文件可能难以管理。ClaudeCode通过支持层级化的CLAUDE.md文件优雅地解决了这个问题。ClaudeCode会在一个级联系统中加载上下文,其查找顺序如下:
- 用户主目录(~/.claude/CLAUDE.md):包含适用于所有项目的个人偏好和全局指令。2. 文目录:从当前工作目录向上查找,回到根目录。这对于在组织或团队层面设定统一标准非常有用。3. 项目根目录(your-repo/CLAUDE.md):这是最常用的位置,定义了整个项目的核心规范。4. 子目录(your-repo/frontend/CLAUDE.md):当ClaudeCode的操作涉及到特定子目录时,它会按需加载该目录下的CLAUDE.md文件,提供更具针对性的上下文。在这个级联系统中,更具体的指令会覆盖更通用的指令。例如,frontend目录下的CLAUDE.md中关于React组件的命名规范,会覆盖项目根目录中更宽泛的命名规则。这种层级结构使得在大型、复杂的代码库中进行精细化的上下文控制成为可能。
使用#命令实时编辑项目的“记忆”
为了让CLAUDE.md的维护过程更加流畅和自然,ClaudeCode提供了一个强大的快捷方式:#命令。在与ClaudeCode的聊天会话中,开发者可以随时输入以#开头的指令,例如:
IMPORTANT: All new API endpoints must include Joi validation.
ClaudeCode会理解这是一个需要持久化的指令,并自动将其添加到当前作用域中最合适的CLAUDE.md文件中。这种有机的工作流使得开发者可以在实际编码和审查过程中,动态地、增量地构建和完善项目的“宪法”,而无需频繁地手动切换和编辑文件。
这种将AI协作规则作为代码进行管理的方法,其意义远超简单的配置。它实际上是将“基础设施即代码”(Infrastructure as Code, IaC)的理念应用到了人机协作领域。在IaC中,服务器、网络和数据库等基础设施是通过机器可读的定义文件(如Terraform或Ansible脚本)来管理和配置的,这带来了自动化、版本控制和可复现性。同样,CLAUDE.md文件就是一个机器(AI)可读的定义文件,它配置了AI代理的“操作环境”31。当这个文件被提交到Git仓库时15,AI的行为准则就变得像项目的其他代码一样,是可版本化、可审查和可追溯的。当新成员加入团队时,他们只需git pull,就能获得与团队其他成员完全一致的、经过验证的AI协作环境。这标志着提示工程从一种个人化的、临时的技巧,演变为一种正式的、可扩展的、协作性的工程学科。管理团队的CLAUDE.md文件,也因此成为一项与管理CI/CD流水线同等重要的架构职责。
第三部分: Claude Code 高级工程工作流
第五章: 面向生产代码的提示工程
提示的光谱: 从零样本到少样本示例
为了从 Claude Code 中获得高质量的生产级代码, 开发者需要掌握一系列提示工程 (Prompt Engineering) 技术。这些技术的核心在于为模型提供恰当的上下文和指导。根据提供示例的数量, 提示可以分为一个光谱 37:
- 零样本提示 (Zero-Shot Prompting): 这是最直接的方式, 即不提供任何示例, 直接给出指令。例如: “编写一个 Python 函数来计算斐波那契数列的第 n 项。” 对于模型在其训练数据中已经非常熟悉、定义明确的任务, 零样本提示通常足够有效 38。- 单样本提示 (One-Shot Prompting): 在指令之后, 提供一个完整的示例 (输入和对应的输出)。这有助于模型理解特定的格式、风格或模糊的指令。例如, 在要求将自然语言转换为 SQL 查询时, 先给出一个转换示例, 可以显著提高后续转换的准确性 37。- 少样本提示 (Few-Shot Prompting): 提供两个或更多的示例。这是处理复杂任务或需要严格遵循特定模式时的首选方法 37。例如, 在代码重构任务中, 提供几个“重构前”和“重构后”的对比示例, 可以有效地教会 Claude Code 你所偏好的代码风格和设计模式。
结构化成功: 使用 XML 标签和形式化规范
对于复杂的请求, 将所有指令、上下文和示例混杂在一起可能会让模型感到困惑。为了提高清晰度和可靠性, 推荐使用 XML 标签来结构化提示 40。这种方法可以将提示的不同部分明确地分离开来。例如, 一个用于 bug 修复的结构化提示可能如下所示:
XML
你是一个资深的 Python 开发者。请修复以下代码中的 bug。 错误发生在当输入列表为空时, 函数会抛出 IndexError。 函数应该在这种情况下返回一个空列表。
def get_first_element(data_list): return data_list
输入:输出:1输入:期望输出:
这种结构化的方法,将提示工程从一种“对话艺术”提升为一种“形式化规范”过程43。通过明确定义输出格式、范围边界和质量指标,开发者可以获得更可预测、更可靠的输出结果。
“探索- 规划- 编码- 提交”的复杂功能工作流
对于任何需要跨越多文件或涉及复杂逻辑的新功能开发,Anthropic官方推荐一个四步工作流,以最大限度地发挥ClaudeCode的代理能力:
- 探索(Explore):首先,要求ClaudeCode阅读和分析所有相关的现有文件、文档甚至图片,但明确指示它不要编写任何代码。例如:“阅读UserService.ts和AuthController.ts,理解当前的用户认证流程。”2. 规划(Plan):接下来,要求ClaudeCode制定一个详细的实施计划。在提示中使用关键词,如“think”、“think hard”或“ultrathink”,可以触发其“扩展思考”模式,分配更多的计算资源来评估不同的方案和边缘案例。例如:“Ultrathink a plan to add two-factor authentication using TOTP”3. 编码(Code):在对计划感到满意后,指示ClaudeCode开始根据该计划实施代码。4. 提交(Commit):最后,要求ClaudeCode提交代码变更,编写符合团队规范的提交信息,并创建一个拉取请求。
这个工作流强制执行了“先思后行”的开发原则,显著提高了复杂任务的成功率。
迭代优化:一种测试驱动的提示设计方法
最有效的提示往往不是一次性写成的。专业的提示工程是一个科学的、迭代的过程,类似于测试驱动开发(TDD)40。
其流程如下:
- 定义成功标准:明确一个好的输出应该具备哪些特征(例如,代码必须通过所有单元测试,性能必须在某个阈值内)。2. 开发测试用例:创建一组输入,用于评估不同版本的提示所产生的输出质量。3. 起草初始提示:编写第一个版本的提示。4. 测试与评估:使用测试用例运行提示,并根据成功标准评估结果。5. 分析与优化:找出输出不符合预期的原因,并据此修改提示(例如,增加更多示例、使用更明
确的指令或添加XML标签)。
- 重复:持续这个循环,直到输出稳定地满足所有成功标准。这种系统化的方法将提示设计从凭感觉的猜测,转变为一个可衡量、可重复的工程过程,是确保AI生成代码质量的关键。
第六章:代理时代下的版本控制:高级Git工作流
超越基本分支:自然语言Git工作流
在代理式开发范式中,版本控制工具如Git不再仅仅是开发者手动操作的对象。通过Claude Code,Git本身也成为可以通过自然语言进行交互的系统。开发者可以委托Claude Code管理整个Git工作流,而不仅仅是编写代码15。
一个典型的自然语言工作流可能如下:
- 创建分支:“为实现用户个人资料页面功能创建一个新的feature分支,遵循feature/JIRA-123-description的命名规范。”2. 实现功能:(执行”探索-规划-编码”工作流)3. 提交变更:“将所有变更提交,撰写一条符合Conventional Commits规范的提交信息,总结本次实现。”4. 创建拉取请求:“创建一个从当前分支到develop分支的拉取请求,将@senior-dev添加为审查者,并在描述中链接到JIRA-123。”这种方式将繁琐的Git命令封装在更高层次的意图之后,让开发者能够更专注于功能本身,同时确保了所有版本控制操作都遵守团队的最佳实践。
释放并行开发:用多个Claude实例掌握gitworktrees
在快节奏的开发环境中,开发者经常需要在多个任务之间切换,例如,在一个新功能的开发过程中,突然需要修复一个紧急的生产环境bug。对于传统的AI助手,这种上下文切换是极其昂贵的。每当开发者切换Git分支时,AI的上下文就会丢失,它需要重新学习和理解新分支的代码库,这个过程被称为“上下文切换税”22。
gitworktree命令为这个问题提供了一个完美的解决方案。它允许开发者将一个Git仓库的多个分支同时检出到文件系统上的不同目录中,而这些目录共享同一个底层的.git数据库22。
结合ClaudeCode,这种技术可以实现真正的并行开发6:
- 开发者可以在一个终端窗口中,进入feature/new-dashboard的工作树目录,并启动一个Claude Code实例来开发新功能。- 当需要修复bug时,开发者可以打开一个新的终端窗口,进入hotfix/login-bug的工作树目录,并启动另一个独立的Claude Code实例。- 这两个Claude Code实例拥有完全隔离的会话和上下文。修复bug的实例可以专注于主分支的稳定代码,而开发新功能的实例则继续在其复杂的特性分支上工作,两者互不干
扰。这种工作流彻底消除了上下文切换的开销,极大地提升了开发者的多任务处理能力。
案例研究:同时管理功能分支与紧急修复
让我们通过一个具体的场景来展示这个工作流的威力:
- 场景开始:开发者正在 ~/projects/my-app-feature 目录(一个 worktree)中与 Claude Code 实例 A 协作,开发一个新的仪表盘功能。Claude Code 实例 A 已经深入理解了与该功能相关的组件、状态管理和 API 调用。2. 紧急中断:生产环境报告了一个紧急的登录 bug。3. 创建修复环境:开发者在主项目目录 ~/projects/my-app 中运行 git worktree add../my-app-hotfix -b hotfix/login -bug main,创建了一个新的工作树。4. 并行工作:开发者打开一个新的终端,进入 ~/projects/my-app-hotfix 目录,并启动一个新的 Claude Code 实例 B。他向实例 B 描述了 bug 的复现步骤。实例 B 开始分析 main 分支的代码,诊断问题并实施修复,而实例 A 在另一个终端中仍然保持着对仪表盘功能的完整上下文,随时可以继续工作。5. 完成修复:bug 修复完成并通过测试。开发者在 my-app-hotfix 目录中让 Claude Code B 提交代码并合并到 main 分支。之后,运行 git worktree remove../my-app-hotfix 清理工作树。6. 无缝回归:开发者切换回原来的终端窗口,实例 A 的会话和上下文完好无损。他可以立即继续开发仪表盘功能,仿佛从未被打断过。这个案例清晰地展示了 git worktree 和多个 Claude Code 实例如何协同工作,将原本会造成严重效率损失的上下文切换,转变为一个流畅、无缝的并行开发流程。
第七章:为质量而架构:规模化测试与重构
用 Claude Code 实施测试驱动开发 (TDD)
测试驱动开发 (TDD) 是一种强大的软件开发实践,它要求在编写功能代码之前先编写失败的测试。Claude Code 的代理能力使其成为实施 TDD 的理想伙伴 33。
一个典型的 TDD 工作流如下:
描述需求:开发者向 Claude Code 描述一个功能需求和其验收标准。2. 生成失败的测试:指示 Claude Code:“为这个功能编写一个单元测试。由于功能尚未实现,这个测试现在应该会失败。” Claude Code 会生成符合项目测试框架(如 Jest, pytest)的测试代码。3. 验证测试失败:开发者(或委托 Claude Code)运行测试,确认它如预期般失败。4. 编写实现代码:指示 Claude Code:“现在编写最少的代码来让刚才的测试通过。”5. 验证测试通过:再次运行测试,确认它现在通过。6. 重构:指示 Claude Code:“重构实现代码和测试代码,以提高可读性和效率。”
重复:为功能的下一个方面重复整个循环。这种方法不仅确保了代码的高测试覆盖率,还强制开发者在编码前清晰地思考需求和接口设计。超越“快乐路径”:为边缘案例和失败生成健壮的测试
人类开发者在编写测试时,往往容易忽略边缘案例和异常情况。Claude Code 在这方面表现出色,因为它能够系统性地思考并生成覆盖各种场景的测试用例7。开发者可以明确地提示Claude Code:
- “为这个函数生成测试,需要覆盖以下边缘案例:输入为空数组、输入包含null或undefined值、输入数组超大。”- “为这个API端点编写集成测试,模拟网络超时、数据库连接失败和无效的用户认证。”Claude Code 生成的测试套件通常比手动编写的更全面,从而显著提高了代码的健壮性。
批判性眼光:识别和缓解AI生成测试中的常见缺陷
尽管AI在生成测试方面很强大,但其输出并非完美无瑕,必须经过人类开发者的严格审查。如果不加批判地接受AI生成的测试,可能会引入一种虚假的安全感。以下是AI生成测试中一些常见的陷阱以及应对策略47:
- 陷阱1:弱断言或无断言:AI有时会生成一个调用了函数但没有进行任何有意义的检查的“测试”。例如,一个测试可能只断言result: $= =$ null,但这并不能证明结果是正确的。
- 缓解策略:审查每个测试,确保断言是具体的、有意义的,能够验证业务逻辑的正确性。- 陷阱2:仅测试“快乐路径”:AI倾向于测试最常见、最理想的输入场景,而忽略了错误处理和边缘案例。
- 缓解策略:如前所述,明确提示AI覆盖特定的边缘案例和错误条件。将审查测试的重点放在异常流程上。- 陷阱3:验证现有Bug:这是一个更隐蔽的问题。AI会根据它正在测试的代码的当前行为来编写测试。如果代码中存在一个bug,AI可能会编写一个“成功”的测试来验证这个错误的行为。
- 缓解策略:始终将测试与原始需求或规范进行对比,而不仅仅是与代码实现对比。TDD是避免此问题的有效方法,因为它强制测试在代码实现之前定义。- 陷阱4:不稳定的测试(Flaky Tests):对于涉及异步操作、并发或计时的代码,AI可能会生成因时序问题而偶尔失败的测试。
- 缓解策略:在审查异步测试时要格外小心,确保使用了正确的机制(如async/await、Promise处理、mock timers)来控制异步流程。
开发者的角色在这里发生了转变:从测试的编写者转变为测试策略的设计者和测试质量的保证者。AI负责繁琐的样板代码生成,而人类则负责确保这些测试是有效和有意义的。
案例研究:策划大规模、多文件的重构项目
Claude Code 的多文件感知能力使其在执行大规模重构任务时尤为强大,这是传统代码补全工具无法企及的33。一个真实的重构案例研究可以分解为以下步骤,这综合了多个来源的实践经验50:
- 理解与文档化:首先,将一个庞大而复杂的遗留代码文件(例如,一个1400行的“上帝”脚本)交给Claude Code,并要求它:“分析这个文件,生成详细的文档来解释其功能、输入和输出。”这一步是建立后续操作的基础。2. 创建测试安全网:在进行任何修改之前,必须有一个全面的测试套件来保证重构不会破坏现有功能。指示Claude Code:“为这个文件生成一个完整的单元测试套件,确保覆盖所有公共方法和主要的逻辑分支。”3. 规划重构策略:要求Claude Code提出一个重构计划:“这个文件违反了单一职责原则。请提出一个计划,将其拆分为多个更小、更专注的模块(例如,一个用于数据获取,一个用于业务逻辑计算,一个用于格式化输出)。列出新文件的名称和每个文件应包含的函数。”4. 执行重构:批准计划后,发出一个高级指令:“执行刚才的重构计划。创建新文件,移动相关函数,并更新整个代码库中所有调用旧函数的地方,使其指向新的模块。”5. 验证与调试:重构完成后,运行在第二步中创建的测试套件。如果出现失败,将失败的测试报告和相关代码片段提供给Claude Code,并要求它进行调试:“这些测试在重构后失败了。请分析原因并修复代码。”
通过这个系统化的流程,开发者可以利用Claude Code将原本需要数天甚至数周才能完成的、高风险的大规模重构任务,安全、高效地完成,从而显著提高代码库的可维护性和质量。
第八章:安全设计:将安全性融入AI工作流
主动安全:编写关注安全的提示和CLAUDE.md规则
在快节奏的AI辅助开发中,安全性不能是事后检查,而必须是设计之初就融入流程的内在属性。实现这一目标的第一道防线是编写具有安全意识的提示。
一个常见的错误是发出模糊的指令,如“创建一个登录函数”。这种提示很可能导致AI生成一个功能上可用但存在严重安全漏洞(如明文密码存储、易受时序攻击)的实现。正确的做法是,在提示中明确提出安全要求51:
“创建一个安全的登录函数,要求:
- 使用Argon2或bcrypt对密码进行哈希处理。2. 对失败的登录尝试实施速率限制,以防止暴力破解。3. 遵循OWASP的会话管理最佳实践。4. 对所有用户输入进行严格的验证和清理。”
为了将这些安全要求制度化,最佳实践是将其固化在CLAUDE.md文件中51。通过在CLAUDE.md中添加一个“安全编码准则”部分,团队可以确保Claude Code在所有开发任务中都默认遵循这些准则。此外,还可以配置规则来防止Claude Code读取敏感文件,例如在CLAUDE.md中明确禁止访问.env文件或包含私钥的目录53。
自动警惕:使用/security-review命令和GitHubActions
除了主动指导,Anthropic还为ClaudeCode提供了强大的自动化安全审查工具,以捕捉潜在的漏洞23。
·/security- review命令:这是一个可以在终端中随时调用的即时安全扫描工具。在提交代码之前,开发者可以运行/security- review,ClaudeCode会利用一个专门训练用于漏洞检测的模型来分析代码库中的变更。它能够识别常见的漏洞模式,包括但不限于:
O SQL注入风险O 跨站脚本(XSS)漏洞O 认证和授权缺陷O 不安全的数据处理O 存在已知漏洞的依赖项
审查完成后,ClaudeCode会提供一份详细的报告,并可以根据开发者的要求自动实施修复方案。
·GitHubAction:为了实现更系统化的安全保障,ClaudeCode提供了GitHubAction集成。配置该Action后,它会在每个新的拉取请求(PullRequest)被创建时自动触发。它会审查PR中的代码变更,并将发现的任何安全问题作为内联评论直接发布在PR中,同时提供修复建议。这创建了一个强制性的、一致的安全审查流程,确保任何代码在合并到主分支之前都经过了基线的安全检查。
理解威胁格局:应用OWASPTop10forLLMs
使用AI进行开发引入了新的安全风险类别。OWASP基金会为此发布了针对大型语言模型应用的Top10安全风险列表(OWASPTop10forLLMApplications),开发者必须对此有所了解54。其中与开发者日常工作最相关的风险包括:
LLM01:提示注入(PromptInjection):攻击者通过精心构造的输入,欺骗模型绕过其安全指令。开发者需要对所有来自外部的、可能被模型处理的输入进行严格的清理和验证。LLM02:不安全的输出处理(InsecureOutputHandling):模型的输出可能包含可执行代码(如JavaScript)或其他可能被下游系统错误解析的内容。开发者必须将模型的输出视为不可信的用户输入,并在使用前进行严格的编码和验证。LLM03:训练数据投毒(TrainingDataPoisoning):虽然这更多是模型提供商的责任,但开发者应意识到,模型可能从其训练数据中学到并复现不安全的代码模式。
理解这些风险有助于开发者在审查AI生成的代码时,保持一种健康的怀疑态度,并采取适当的防御措施。
处理敏感代码和预防漏洞的最佳实践
将AI集成到开发工作流中,需要一套全面的防御策略,将自动化工具与人类监督相结合51。
·将AI视为初级开发者:永远不要盲目信任AI生成的代码。每一行由AI编写的代码都应经过与审查初级开发者提交的PR同等甚至更严格的审查。
集成静态应用安全测试 (SAST): 在 CI/CD 流水线中集成 SAST 工具 (如 SonarQube, Snyk), 以自动扫描代码中的常见漏洞。- 审计依赖项: AI 可能会引入新的第三方库。使用 npm audit 或类似的工具定期扫描项目依赖, 检查是否存在已知漏洞。- 维护强大的测试套件: 全面的单元测试和集成测试是抵御 AI 引入回归错误和逻辑漏洞的最有效防线。测试套件应包括专门的安全测试用例, 例如验证访问控制和输入清理的有效性。
最终,AI是一个强大的加速器,但安全责任最终仍在开发者身上。一个成功的安全策略是利用AI提高发现和修复漏洞的效率,同时依靠严格的工程实践和人类的批判性思维作为最后的防线。
第九章: 自文档化代码库
从代码到清晰: 生成文档字符串、注释和 README
软件开发中的一个长期痛点是保持文档与代码同步。Claude Code 在这方面展现出卓越的能力, 能够将文档生成过程从一项繁琐的负担转变为开发流程中一个自然的、自动化的环节16。Claude Code 不仅仅是基于函数签名生成模板, 它能够深入分析代码的逻辑和上下文, 生成高质量、内容丰富的文档59:
- 结构化文档字符串 (Docstrings): 它可以为函数、类和模块生成符合特定语言规范 (如 Python 的 PEP 257, Java 的 Javadoc) 的文档字符串。这些文档字符串不仅描述了参数和返回值, 还解释了函数的目的和行为。- 内联注释: 对于代码中特别复杂或不直观的部分, 可以要求 Claude Code 添加内联注释来解释其背后的逻辑。- README 文件: 它可以扫描整个项目, 生成一个全面的 README.md 文件, 包括项目简介、安装步骤、使用示例和配置说明。
可视化架构: 创建图表和高层概览
对于复杂的系统, 文本描述往往不足以传达其结构。Claude Code 的高级文档能力还包括从代码生成可视化的架构表示59。
开发者可以提出这样的要求:
- “分析 services 目录下的所有文件, 解释不同服务之间的依赖关系和交互模式。”- “为这个用户认证流程生成一个序列图 (sequence diagram) 的 Mermaid 或 PlantUML 描述。”- “基于这个模块的错误处理逻辑, 创建一个流程图来描述不同的失败路径。”
这种能力极大地降低了理解和维护复杂代码库的认知门槛, 尤其对于新加入团队的成员来说, 是快速上手的宝贵工具。
保持文档常青:持续更新的工作流
文档的最大挑战在于其”时效性”。一旦编写完成,文档就很容易与快速选代的代码脱节。为了解决这个问题,需要将文档更新集成到日常开发工作流中。
集成到提交流程:在委托ClaudeCode提交代码时,可以加入一个额外的指令:“在提交之前,请更新所有受影响的函数和类的文档字符串,并更新README.md的相关部分以反映这些变更”59。·使用CLAUDE.md强制执行标准:在CLAUDE.md文件中明确规定文档标准,例如:”所有公共函数都必须有符合Google风格的文档字符串,并包含至少一个使用示例。“这将确保ClaudeCode在生成或修改代码时,会自动遵守这些文档规范31。
通过这些工作流,团队可以朝着”自文档化代码库”的理想迈进,其中文档不再是代码的附属品,而是与代码同步生成和演进的、活的产物。
第四部分:综合与展望
第十章:开发者的一天:完整的端到端项目工作流
为了将前面章节中讨论的所有最佳实践融会贯通,本章将通过一个叙事性的、端到端的场景,展示一位开发者如何利用ClaudeCode高效、高质量地完成一个新功能的开发。场景:开发者Anna需要为一个现有的电商应用添加”愿望单”功能。
1.步骤1:环境设置(Setup)
Anna首先为这个新功能创建一个隔离的开发环境。她没有直接在主分支上工作,而是使用了gitworktree:Bashgitworktree add../wishlist- feature - b feature/PROJ- 456- wishlist然后,她进入新的工作树目录../wishlist- feature,并启动了一个专用于此功能的ClaudeCode会话。
2.步骤2:规划(Planning)
Anna切换到计划模式,并向ClaudeCode描述了她的高层目标:”ultrathink a plan to add a wishlist feature. It should allow users to add/remove products to their personal wishlist. The wishlist should be accessible from the user’s profile page. We need a new database table, new API endpoints, and frontend components in React. Refer to our existing CLAUDE.md for API design and component style guidelines.”ClaudeCode经过深入思考,生成了一份详细的计划,包括数据库schema、REST API端点定义(POST/api/wishlist, DELETE/api/wishlist/:productId等)、React组件结构(WishlistPage, AddToWishlistButton)以及状态管理策略。Anna审查了计划,并
提出了一些微调,Claude Code 相应地更新了计划。
步骤3:测试驱动开发(TDD)
步骤 3: 测试驱动开发 (TDD)- Anna 批准了计划。她没有直接要求实现功能,而是遵循 TDD 原则: “Based on the plan, first write the backend integration tests for the new API endpoints using Jest and Supertest. These tests should fail initially.”- Claude Code 生成了测试文件,Anna 运行后确认所有测试都失败了。
步骤4:实现(Implementation)
步骤 4: 实现 (Implementation)- 现在,Anna 指示 Claude Code 编写功能代码: “Implement the backend logic (database model, controller, routes) to make the tests pass. Remember to follow the SOLID principles outlined in our CLAUDE.md.”- Claude Code 编写了后端代码。Anna 再次运行测试,这次所有测试都通过了。她以类似的方式,通过 TDD 流程完成了前端组件的开发。
步骤5:安全审查(Security)
步骤 5: 安全审查 (Security)- 在准备提交代码之前,Anna 运行了内置的安全扫描:/security-review- Claude Code 报告了一个潜在的授权问题:删除愿望单项目的端点没有严格验证操作者是否为项目的所有者。Anna 指示 Claude Code 修复了这个问题。
步骤6:文档化 (Documentation)
步骤 6: 文档化 (Documentation)- 功能完成后,Anna 要求 Claude Code 完善文档: “Generate JSDoc comments for all new backend functions and React prop-types for the frontend components.”
步骤7:提交与拉取请求 (Commit & PR)
步骤 7: 提交与拉取请求 (Commit & PR)- 最后,Anna 将整个流程的收尾工作委托给 Claude Code: “Commit all changes with a conventional commit message. Then, create a pull request to the develop branch, title it ‘feat: Add wishlist functionality’, and add @lead-dev as a reviewer.”- Claude Code 执行了 Git 操作,并创建了 PR。由于团队配置了 Claude Code 的 GitHub Action, PR 创建后,自动化的安全和代码风格审查再次被触发,为人工审查提供了额外的保障。
通过这个流程,Anna不仅快速地完成了功能开发,而且确保了代码的高质量、高测试覆盖率、安全性和良好的文档。她的大部分时间都花在了战略性的指导和审查上,而不是繁琐的编码细节。
第十一章:代理式编码的未来
新兴能力与 Claude Code 的未来之路
Claude Code 的出现标志着软件开发范式转变的开始,但这仅仅是一个开端。Anthropic 已经规划了未来的发展方向,旨在进一步增强其代理能力:
- 增强的工具使用:未来的版本将拥有更可靠、更强大的工具调用能力,能够与更多类型的外部 API 和服务进行交互。- 长时运行命令:支持需要较长时间才能完成的命令(如复杂的构建或数据处理任务),使
Claude Code 能够管理和监控整个流程。
- 子代理 (Sub-agents): 这是一个令人兴奋的方向。开发者或许可以将一个复杂的任务分解,并将其委托给一个由多个专门的“子代理”组成的团队。例如,一个“数据库代理”负责所有与数据库相关的操作,一个“UI 代理”负责前端实现,而一个“测试代理”则专注于编写和运行测试。主代理将负责协调这些子代理的工作。
为 AI 原生软件开发的未来做准备
像 Claude Code 这样的代理式工具正在深刻地重塑软件开发者的角色。未来的开发者将越来越少地作为代码的直接创作者,而更多地扮演以下角色:
- 系统架构师:负责将模糊的业务需求分解为清晰的、可由 AI 执行的子任务。- AI 协调员:精通高级提示工程,能够有效地指导、配置和协调 AI 代理(或代理团队)来完成复杂的项目。- 质量保证者:拥有敏锐的批判性思维,能够严格审查 AI 生成的所有产物——包括代码、测试、文档和架构设计——以确保其质量、安全性和可维护性。
在这个新时代,最重要的技能不再是快速键入代码的能力,而是问题分解、战略性提示和对 AI 产出的批判性评估能力。那些能够掌握这些技能,并学会与 AI 代理高效协作的开发者,将在未来的软件工程领域中占据核心地位。代理式编码的浪潮已经到来,它带来的不仅是生产力的飞跃,更是对软件开发这门手艺本身的重新定义。
引用的著作
- Claude 3.7 Sonnet and Claude Code \Anthropic, 访问时间为八月 30, 2025, https://www.anthropic.com/news/claude-3-7-sonnet2. ChatGPT vs Claude: Two Giants, Different Strengths - Neontri, 访问时间为八月 30, 2025, https://neontri.com/blog/chatgpt-vs-claude/3. Boost Your Coding Efficiency with Claude’s Secret Features - Sidetool, 访问时间为八月 30, 2025, https://www.sidetool.co/post/boost-your-coding-efficiency-with-claude-s-secret-features/4. Claude vs ChatGPT: AI Coding, Features, and Pricing Comparison (2025) - Knack, 访问时间为八月 30, 2025, https://www.knack.com/blog/claude-vs-chatgpt-comparison/5. Claude 3.7 Sonnet: An In-Depth Analysis - SmythOS, 访问时间为八月 30, 2025, https:// Smythos.com/updates/claude-3-7-sonnet-an-in-depth-analysis/6. Claude Code: Best practices for agentic coding - Anthropic, 访问时间为八月 30, 2025, https://www.anthropic.com/engineering/claude-code-best-practices7. Supercharge Your Workflow: Mastering Claude Code with Practical Tips and Tricks, 访问时间为八月 30, 2025, https://htdocs.dev/posts/supercharge-your-workflow-mastering-claude-code-with-practical-tips-and-tricks/8. I tested Claude vs GitHub Copilot with 5 coding prompts - Here’s my winner, 访问时间为八月 30, 2025,
https://techpoint.africa/guide/claude- vs- github- copilot- for- coding/
How does Claude Code compare to GitHub Copilot? - Milvus, 访问时间为八月 30, 2025, https://milvus.io/ai-quick-reference/how-does-claude-code-compare-to-github-copilot
Claude Code overview - Anthropic API, 访问时间为八月 30, 2025, https://docs.anthropic.com/en/docs/claude-code/overview
Anthropic Economic Index: AI’s impact on software development, 访问时间为八月 30, 2025, https://www.anthropic.com/research/impact-software-development
Deploying Claude Code vs GitHub Copilot for developers at a large (1000+ user) enterprise, 访问时间为八月 30, 2025, https://www.reddit.com/r/ClaudeAI/comments/1mOyiab/deploying_claude_code_vs_github_copilot_for/
How to Start Vibe Coding Using Claude? - Fueler, 访问时间为八月 30, 2025, https://fueler.io/blog/how-to-start-vibe-coding-using-claude
Integrate Claude with VS Code: A Simple Step-by-Step Guide - Arsturn, 访问时间为八月 30, 2025, https://www.arsturn.com/blog/your-step-by-step-guide-to-integrating-claude-wi-th-vs-code
Cooking with Claude Code: The Complete Guide - Sid Bharath, 访问时间为八月 30, 2025, https://www.siddharthbharath.com/claude-code-the-complete-guide/
Claude Code Tutorial: How to Generate, Debug and Document Code with All Codecademy, 访问时间为八月 30, 2025, https://www.codecademy.com/article/claude-code-tutorial-how-to-generate-debug-and-document-code-with-ai
Set up Claude Code - Anthropic API, 访问时间为八月 30, 2025, https://docs.anthropic.com/en/docs/claude-code/setup
How I use Claude Code (+ my best tips) - Builder.io, 访问时间为八月 30, 2025, https://www.builder.io/blog/claude-code
3 Tips of Getting the Most Out of Claude Code | Nathan Onn, 访问时间为八月 30, 2025, https://www.nathanonn.com/3-tips-of-getting-the-most-out-of-claude-code/
Claude Code: A Guide With Practical Examples - DataCamp, 访问时间为八月 30, 2025, https://www.datacamp.com/tutorial/claude-code
How to use Claude Code for beginners - YouTube, 访问时间为八月 30, 2025, https://www.youtube.com/watch?v=U_vwvfQBhVGY
Mastering Git Worktrees with Claude Code for Parallel Development …, 访问时间为八月 30, 2025, https://medium.com/@dtunai/mastering-git-worktrees-with-claude-code-for-parallel-development-workflow-41dc91e645fe
Automate security reviews with Claude Code \ Anthropic, 访问时间为八月 30, 2025, https://www.anthropic.com/news/automate-security-reviews-with-claude-code
Claude Code for VSCode - Visual Studio Marketplace, 访问时间为八月 30, 2025,
https://marketplace.visualstudio.com/items?itemName=anthropic.claude- code25. Add Claude Code to your IDE - Anthropic API, 访问时间为八月 30, 2025, https://docs.anthropic.com/en/docs/claude- code/ide- integrations26. Setting Up Claude Code in VS Code | AWS Builder Center, 访问时间为八月 30, 2025, https://builder.aws.com/content/2v5sqf1SSJ89ke01CbCE6o4GZKzs/getting- up- claude- code- in- vs- code27. Claude Code [Beta] Plugin for JetBrains IDEs, 访问时间为八月 30, 2025, https://plugins.jetbrains.com/plugin/27310- claude- code- beta- 28. Claude Code IDE integrations for JetBrains IDEs and VS Code - YouTube, 访问时间为八月 30, 2025, https://www.youtube.com/watch?v=5xciwLNX_A829. Any good experiences with the Claude Code plugin? : r/Jetbrains - Reddit, 访问时间为八月 30, 2025, https://www.reddit.com/r/Jetbrains/comments/1kv6yj0/any_good_experiences_with_the_claude_code_plugin/30. ClaudeMind Plugin for JetBrains IDEs, 访问时间为八月 30, 2025, https://plugins.jetbrains.com/plugin/25082- claudemind31. What is CLAUDE.md in Claude Code - ClaudeLog, 访问时间为八月 30, 2025, https://www.claudelog.com/faqs/what- is- claude- md/32. What’s a Claude.md File? 5 Best Practices to Use Claude.md for Claude Code - Apidog, 访问时间为八月 30, 2025, https://apidog.com/blog/claude- md/33. Mastering Claude Code: The Ultimate Guide to AI- Powered Development | by Kushal Banda, 访问时间为八月 30, 2025, https://medium.com/@kushalbanda/mastering- claude- code- the- ultimate- guide- to- ai- powered- development- afccf1bdbd5b34. Claude Code - Mintlify, 访问时间为八月 30, 2025, https://mintlify.com/docs/guides/claude- code35. How I use Claude Code - Medium, 访问时间为八月 30, 2025, https://tylerburnam.medium.com/how- i- use- claude- code- c73e5bfcc30936. Maximising Claude Code: Building an Effective CLAUDE.md - Maxitect Blog, 访问时间为八月 30, 2025, https://www.maxitect.blog/posts/maximising- claude- code- building- an- effective- claudemod37. Zero- Shot, One- Shot, and Few- Shot Prompting, 访问时间为八月 30, 2025, https://learnprompting.org/docs/basics/few_shot38. Few- Shot Prompting: Techniques, Examples, and Best Practices …, 访问时间为八月 30, 2025, https://www.digitalocean.com/community/tutorials/_few- shot- prompting- techniques- examples- best- practices39. Zero- Shot Prompting - Prompt Engineering Guide, 访问时间为八月 30, 2025, https://wwwpromptingguide.ai/techniques/zeroshot40. Prompt engineering overview - Anthropic | PDF - Scribd, 访问时间为八月 30, 2025, https://www.scribd.com/document/859440347/Prompt- engineering- overview- Anthropic
Generative AI and Prompt Engineering with Anthropic’s Claude - Latenode, 访问时间为八月30,2025, https://latenode.com/blog/generative-ai-and-prompt-engineering-with-anthropi cs-claude
Prompt engineering overview - Anthropic, 访问时间为八月30,2025, https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering/overvieww
Claude 4 Prompt Engineering Best Practices | Vinci Rufus, 访问时间为八月30,2025, https://www.vincirufus.com/posts/claude-4-prompt-engineering-best-practices/
Claude Prompt Engineering - Confuse The Machine, 访问时间为八月30,2025, https://confusethemachine.com/claude-prompt-engineering
Can Claude Code help write unit tests? - Milvus, 访问时间为八月30,2025, https://milvus.io/ai-quick-reference/can-claude-code-help-write-unit-tests
How Anthropic teams use Claude Code \ Anthropic, 访问时间为八月30,2025, https://www.anthropic.com/news/how-anthropic-teams-use-claude-code
AI-Driven Testing Best Practices - foobjay, 访问时间为八月30,2025, https://foobjay.io/today/ai-driven-testing-best-practices/
Home \ Anthropic, 访问时间为八月30,2025, https://www.anthropic.com/claude-explains/improve-code-maintainability-using-claude
Refactoring with claude code: r/ClaudeAI - Reddit, 访问时间为八月30,2025, https://www.reddit.com/r/ClaudeAl/comments/lpelvi/refactoring_with_claude_code/
Refactoring with Claude. A concrete and relatable example of how …, 访问时间为八月30,2025, https://medium.com/@jbelis/refactoring-with-claude-b690a364d2f0
Al Code Security: 4 Best Practices Every Developer Should Know, 访问时间为八月30,2025, https://www.stackhawk.com/blog/4-best-practices-for-ai-code-security-a-developers-guide/
Generate More Secure Code With AI-Powered Tools - Auth0, 访问时间为八月30,2025, https://auth0.com/blog/prompt-engineering-security/
Creating a security.md for all Claude code vibe coders: r/ClaudeAl - Reddit, 访问时间为八月30,2025, https://www.reddit.com/r/ClaudeAl/comments/1m2fdgr/creating_a_security.md_for_all_claude_code_vibe/
What are the OWASP Top 10 risks for LLMs? | Cloudflare, 访问时间为八月30,2025, https://www.cloudflare.com/learning/ai/owasp-top-10-risks-for-llms/
OWASP Top 10 LLM, Updated 2025: Examples & Mitigation Strategies - Oligo Security, 访问时间为八月30,2025, https://www.oligo.security/academy/owasp-top-10-llm-updated-2025-examples-and-mitigation-strategies
OWASP Top 10 LLM: How to test your Gen AI app in 2025 - Evidently AI, 访问时间为八月30,2025, https://www.evidentlyai.com/blog/owasp-top-10-llm
Home - OWASP Gen AI Security Project, 访问时间为八月 30, 2025, https://genai.owasp.org/58. Security - Anthropic API, 访问时间为八月 30, 2025, https://docs.anthropic.com/en/docs/claude-code/security59. Can Claude Code generate documentation from code? - Milvus, 访问时间为八月 30, 2025, https://milvus.io/ai-quick-reference/can-claude-code-generate-documentation-from-code60. Mastering Claude Code - The Developer’s AI Assistant, 访问时间为八月 30, 2025, https://www.shawnmayzes.com/articles/mastering-claude-code-the-developers-ai-assistant/61. The use of Claude Code in SciML repos - Tooling - Julia Programming Language, 访问时间为八月 30, 2025, https://discourse.julialang.org/t/the-use-of-claude-code-in-sciml-repos/13100962. 20+ Real Use Cases That Prove Claude Code Is a Game-Changer | by Agen.cy - Medium, 访问时间为八月 30, 2025, https://medium.com/@agencyai/20-real-use-cases-that-prove-claude-code-is-a-game-changer-46ceefaf19ed