minimind
这里使用默认配置,预训练1个epoch,sft2个epoch复现结果。
使用damodel提供服务
按小时计费
- 预训练
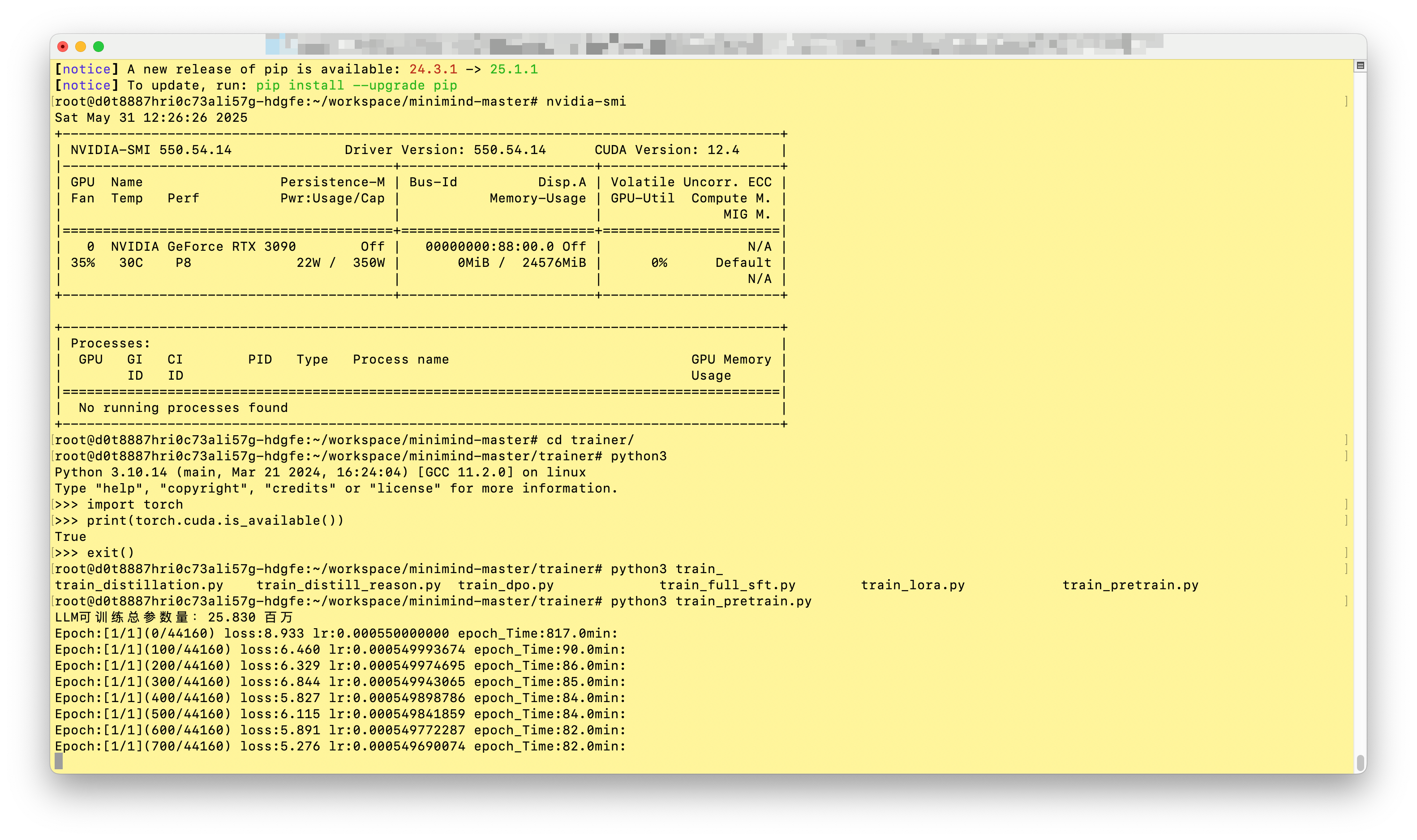
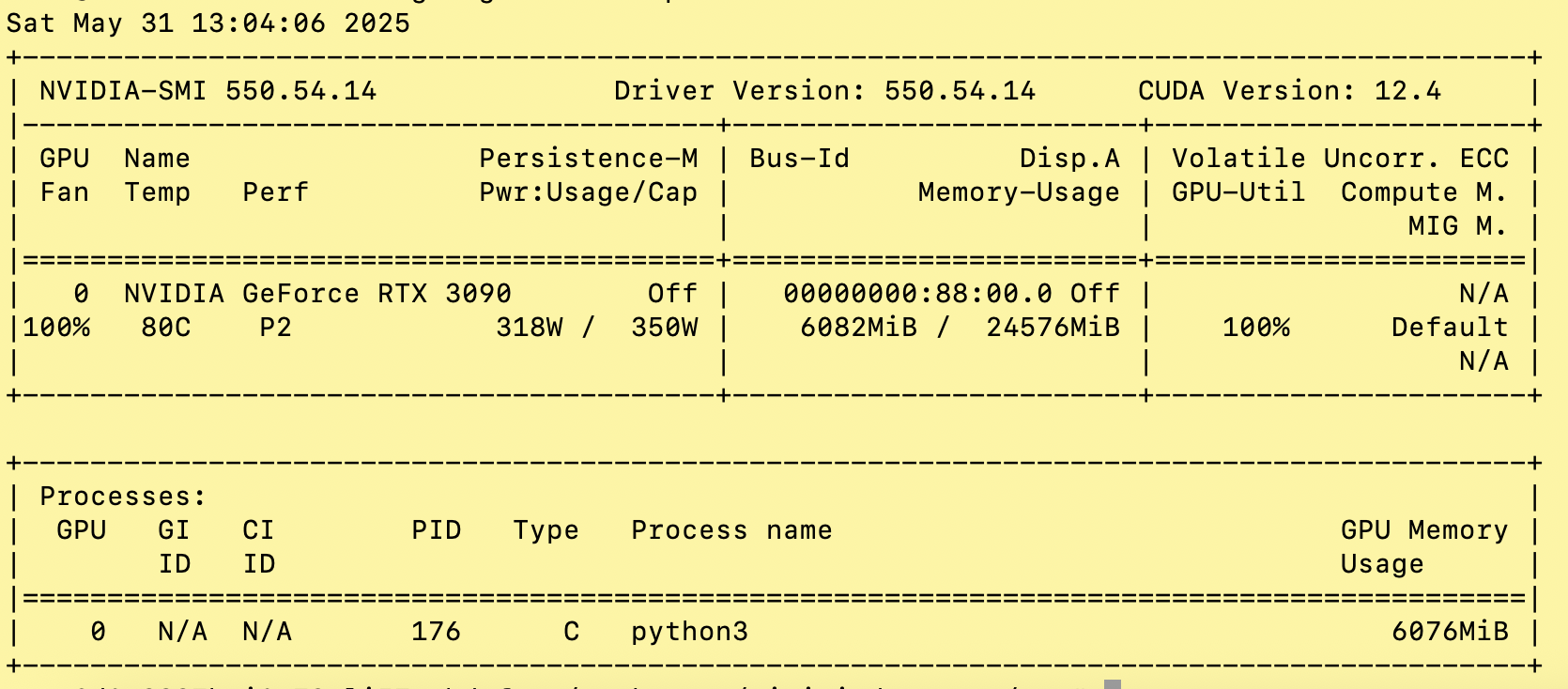
sft
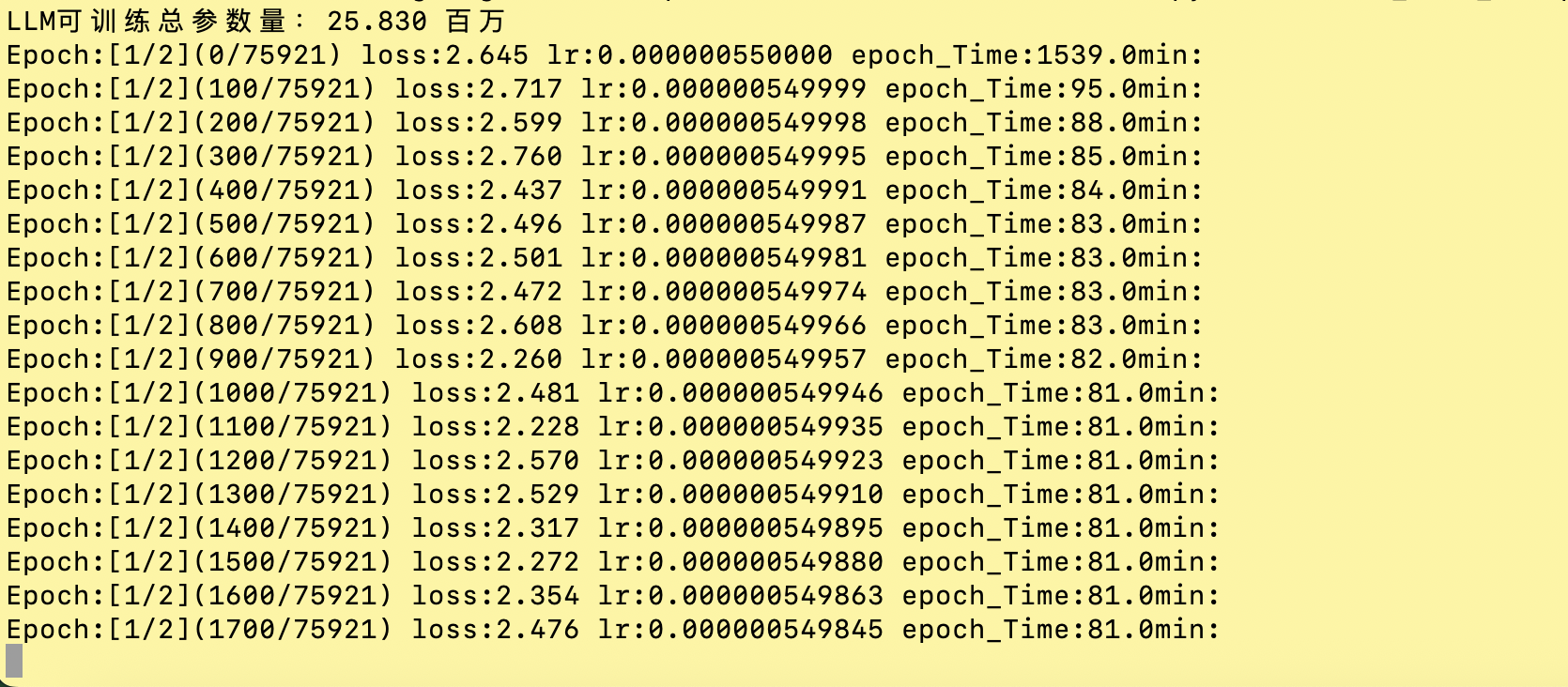
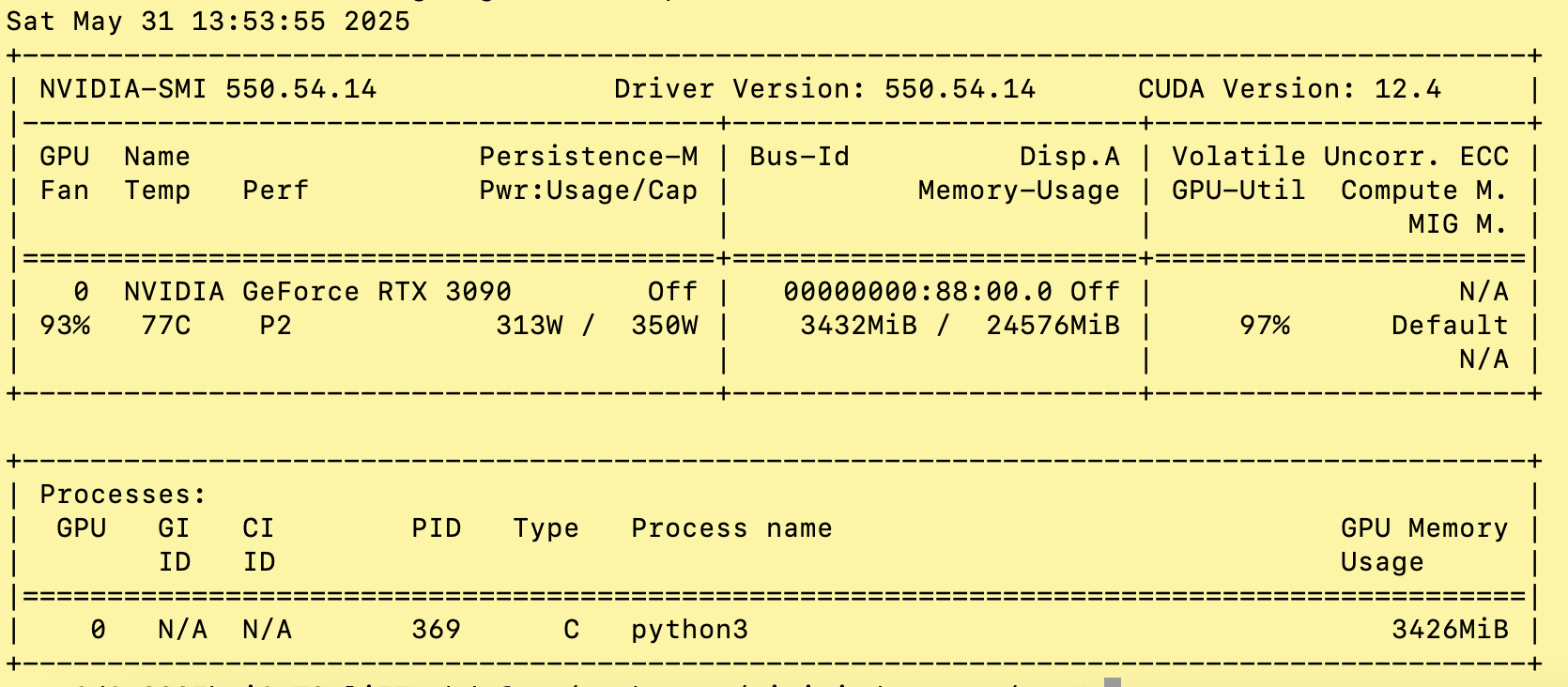
验证

总共花费5.15,实际没花钱,注册送了20代金券。
使用apktool反编译搜索到totp相关信息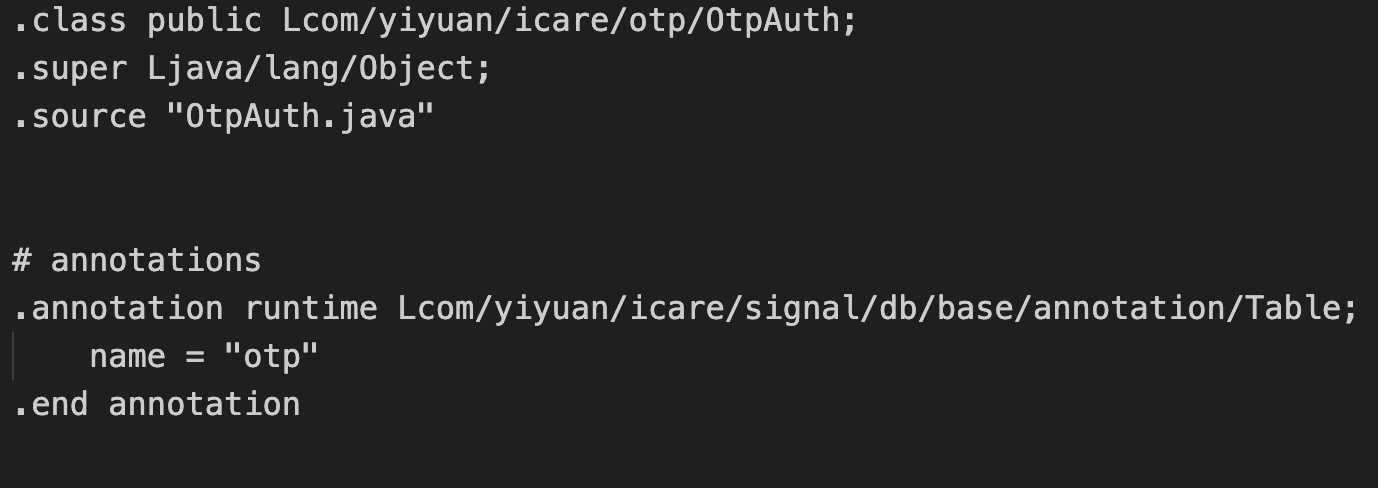
安装模拟器获取root权限,使用adb shell获取/data/data/应用名/databases/下的应用数据库,获取到原始totp密钥
在脚本里使用
1 | import pyotp |
1 | package main |

感谢deepseek
1 | import cv2 |
1 between 0 and 4 的编译结果:
1 | package org.kie.dmn.feel.codegen.feel11.genadeb1f468481413bbc5bfd45c3422978; |
between调用的方法是org.kie.dmn.feel.codegen.feel11.CompiledFEELSemanticMappings.between方法,是预先写好的。
我觉得相比于ast的方式,把一些变量放在类里面了。编译完之后也可以直接加载使用。
The retrieved
CompiledFEELExpressioncould be a statically-interpretedInterpretedExecutableExpression(that wraps the originalBaseNodeast) or could be a dynamically-code-generatedCompiledExecutableExpression.
In the first case, evaluation is executed by the DMN code as it is statically defined.
In the latter case, code is generated out of the given model. In that code, some variable will be directly written in the generated, speeding up its execution.
https://sentinelguard.io/zh-cn/docs/system-adaptive-protection.html
1 | // total thread |
qps * rt==当前的线程数就是最佳的负载。如果当前线程数据>qps * rt可以认为新进来的请求会产生积压。
qps * rt 就是当前系统的消费能力。线程数就是当前的生产能力。
正常还是需要组合其他策略使用。
只能在入口使用是因为需要当前cpu负载激发。
1 | if (highestSystemLoadIsSet && getCurrentSystemAvgLoad() > highestSystemLoad) { |
但实际上是不是也可以对下游也这么干?现在都是微服务架构,如何根据下游的能力实时的进行出口限流?
https://github.com/kiegroup/drools/tree/main/kie-dmn/kie-dmn-feel:
antlr4词法解析,通过vistor生成抽象语法树,执行。但是可以用javaparser将ast生成java代码,再编译成class执行。其原理效果还不太明确。
例子:
https://stackoverflow.com/questions/29971097/how-to-create-ast-with-antlr4
https://camunda.github.io/feel-scala/:
用的scala实现
readme里有一段最近被删掉了。
The following resources can help to understand some general concepts behind the implementation:
2024-08-30/2024-09-03
总自费3000元左右。
设备:A6700 18-135






















































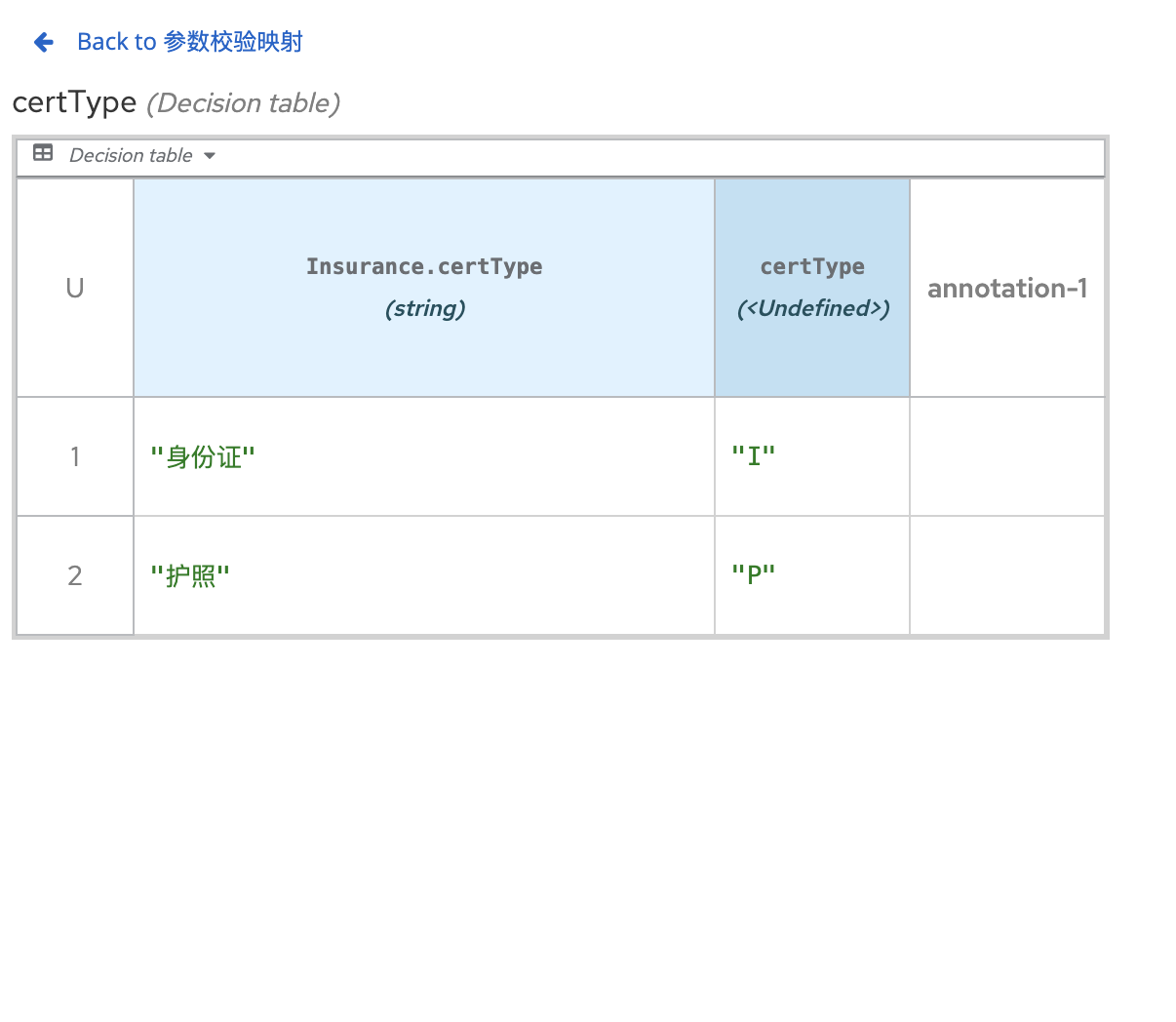
决策模型和符号(DMN™)是由 OMG® 制定的一项标准,它提供了一种通用且可视化的符号,所有用户和角色都可以轻松理解。借助 DMN,业务分析师可以定义初始决策需求,然后将更详细的决策模型形式化;技术开发人员可以使用可移植的执行语义来自动执行任何流程中的决策,而业务利益相关者可以管理和监控这些决策。
https://www.omg.org/spec/DMN/1.5/Beta1
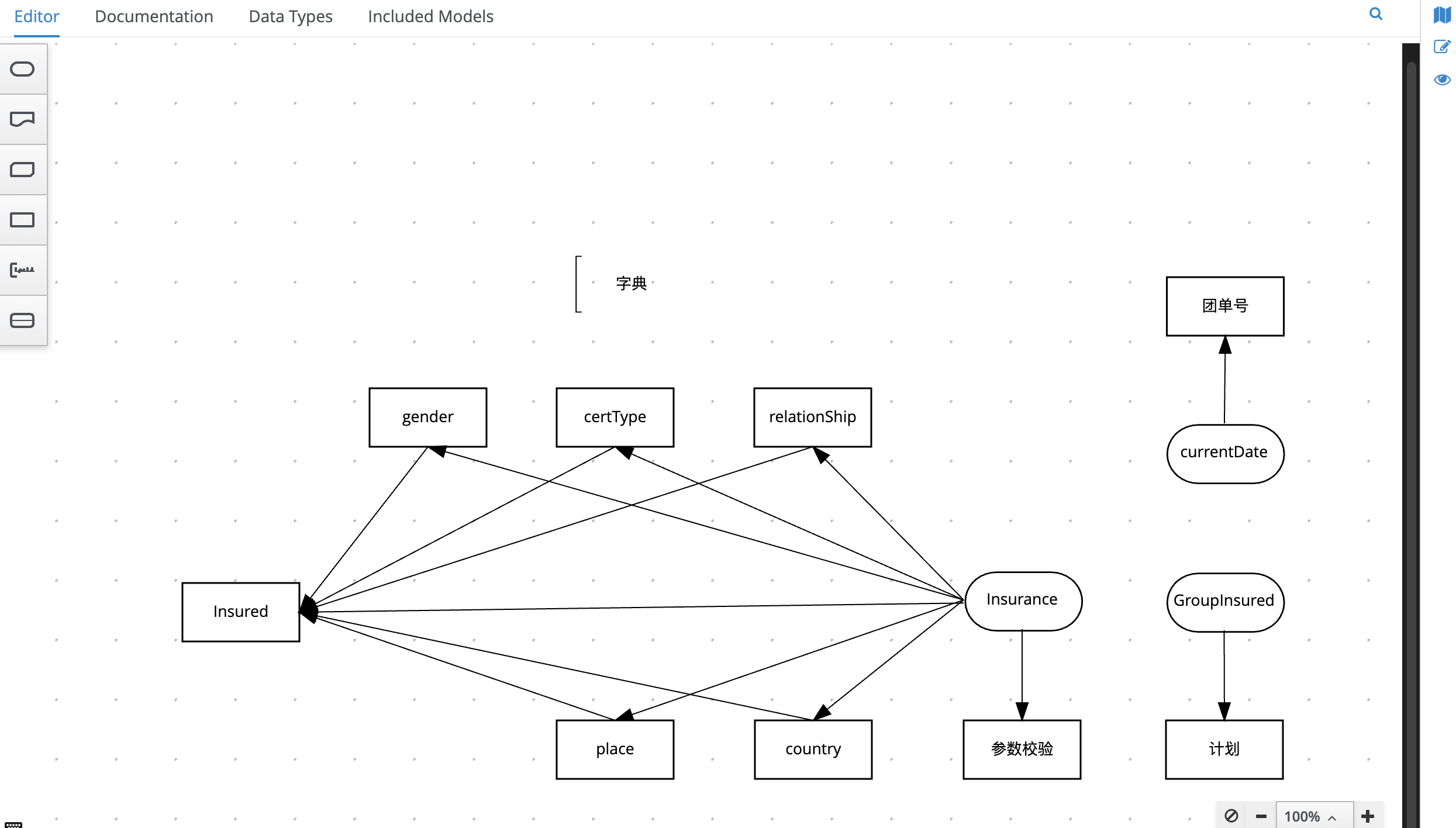
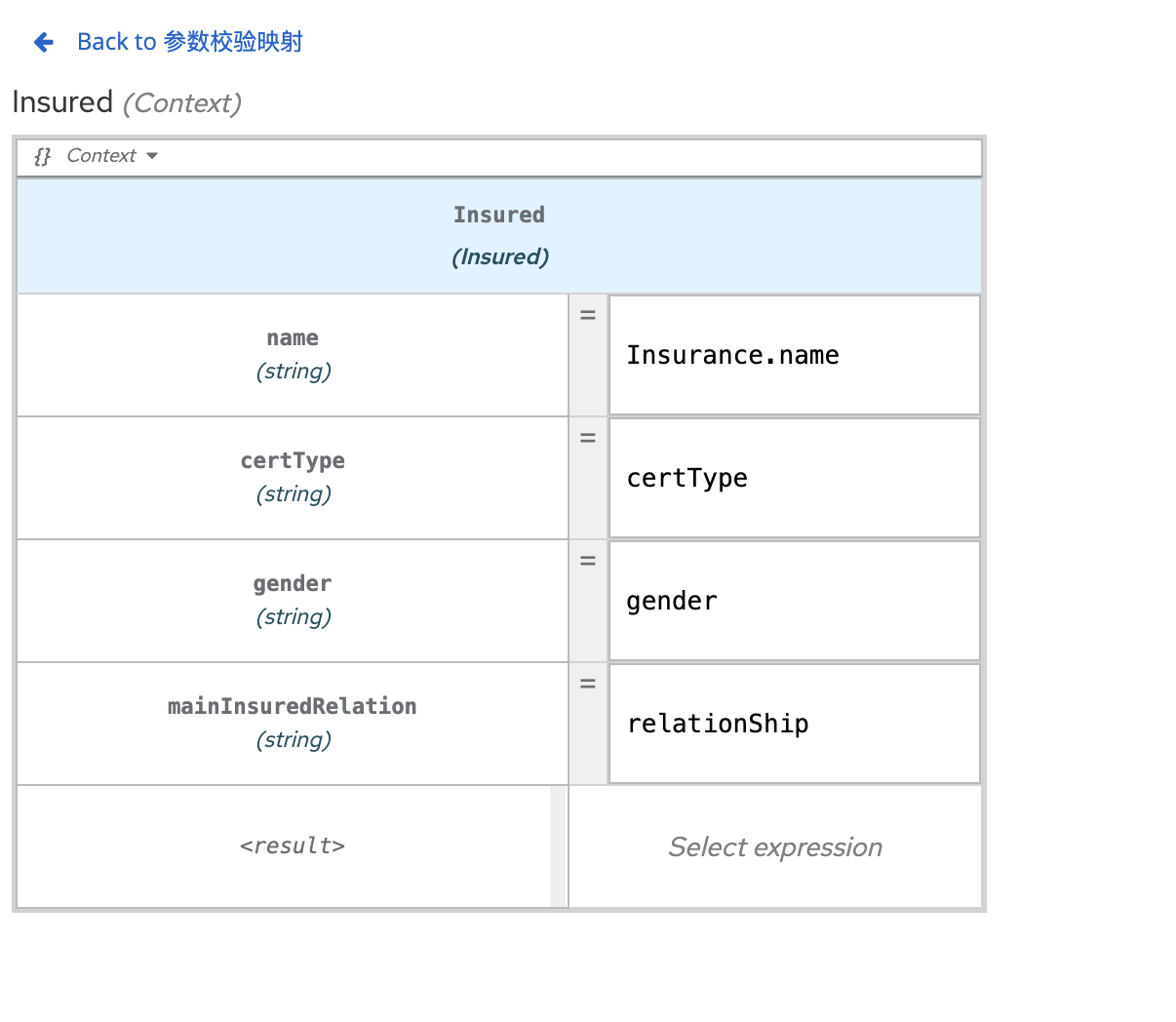


1 |
https://marketplace.visualstudio.com/items?itemName=kie-group.dmn-vscode-extension
https://bpmn.io/toolkit/dmn-js/
@kogito-tooling/kie-editors-standalone
DMN 更易于理解和维护,更适合业务人员参与
DMN 支持图形化的决策模型,更直观
DMN 提供了更丰富的决策元素和功能,更灵活
DMN 标准化程度更高,更易于与其他系统集成